




















Das Fraunhofer-Institut für Intelligente Analyse- und Informationssysteme IAIS entwickelte zusammen mit Partnern ein grosses KI-Sprachmodell als frei verwendbares Open-Source-Modell.
«Teuken-7B» wurde mit den 24 Amtssprachen der EU trainiert und umfasst sieben Milliarden Parameter. Die Software ist ein grosses KI-Sprachmodell und sie darf als Open-Source frei verwendet werden.
Diese Abbildung zeigt die Sprachverteilung von Teuken-7B-v0.4. Neben Code enthält die Software 50 % nicht-englischen Text aus 23 Ländern und 40 % englische Pretraining-Daten. Damit unterscheidet sich Teuken wesentlich von anderen mehrsprachigen Modellen, die erst später mit weiteren Sprachen ergänzt werden.
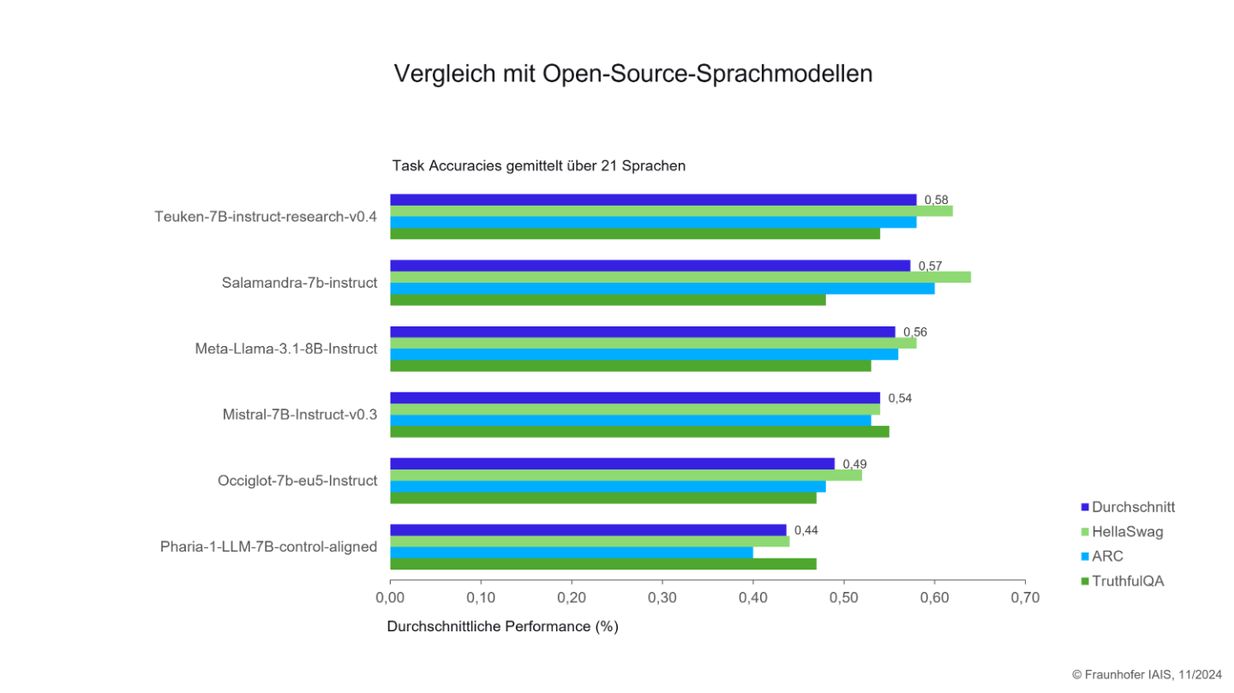
Vergleich mit Open-Source-Sprachmodellen, © Fraunhofer IAIS, 11/2024
Dieses Diagramm zeigt die Performance für den jeweiligen Benchmark für 21 europäische Sprachen und den Mittelwert aller drei Benchmarks. Teuken liegt im Durchschnitt knapp an der Spitze, bei den anderen drei Benchmarks an zweiter Stelle.
Aufpreis im Vergleich zu Englisch mit Llama 3, © Fraunhofer IAIS, 11/2024
Teuken benötigt die geringste Menge an zusätzlicher Rechenleistung, um einen englischen Text mit dem zum Sprachmodell gehörenden Tokenizer zu verarbeiten (in % im Vergleich zu Llama 3). Die Software verursacht somit einen tieferen Aufpreis für multilinguale Anfragen.
Multilinguale Entwicklung
Teuken-7B gehört zu den wenigen KI-Sprachmodellen, die multilingual entwickelt wurden. Es arbeitet über mehrere Sprachen hinweg stabil und zuverlässig. Als Open-Source-Modell kann Teuken an eigene Bedürfnisse angepasst werden, ohne dass sensible Daten das Unternehmen verlassen.
Neben dem Modelltraining widmen sich die Forscher auch der Energie- und Kosteneffizienz der Software. Dazu wurde ein «Tokenizer» entwickelt, der Wörter in einzelne Wortbestandteile zerlegt. Je weniger Token, desto (energie-)effizienter und schneller generiert ein Sprachmodell die Antwort. Zudem werden mit dem Tokenizer die Trainingskosten reduziert.
Teuken-7B ist auch über die Gaia-X Infrastruktur zugänglich. Im Gaia-X-Ökosystem können sich unterschiedliche Dienstanbieter und Dateneigentümer miteinander verbinden. Deren Daten verbleiben stets beim Eigentümer und sie werden nur nach festgelegten Bedingungen geteilt. Prof. Dr.-Ing. Bernhard Grill, Institutsleiter am Fraunhofer IIS, betont die Bedeutung für sicherheitsrelevante Anwendungen: «Mit dem hier veröffentlichten, von Grund auf vollkommen eigenständig trainierten Sprachmodell demonstrieren die Projektpartner ihre Fähigkeit, eigene grosse Modelle erzeugen zu können.» Für Unternehmen können so individuelle KI-Lösungen geschaffen werden, die ohne Black-Box-Komponenten auskommen.
Training mit Supercomputer
Trainiert wurde Teuken-7B mit dem Supercomputer JUWELS am Forschungszentrum Jülich. Die in OpenGPT-X entstandene Technologie bietet den beteiligten Partnern auch zukünftig die Basis für das Training weiterer eigener Modelle.
OpenGPT-X zeigt, wie mit einer breiten Forschungsbasis Grundlagen für neue Technologien entstehen, von denen alle profitieren können. Bis zum Abschluss des Forschungsprojektes am 31. März 2025 wird es weitere Optimierungen und Evaluierungen geben.
Nutzung und Download von Teuken-7B
Entwickler aus der Wissenschaftscommunity oder Unternehmen können Teuken-7B bei Hugging Face kostenlos herunterladen und in der eigenen Entwicklungsumgebung damit arbeiten. Mit «Instruction Tuning» wurde das Modell für den Chat optimiert. Dadurch können grosse KI-Sprachmodelle Anweisungen richtig versteht, was vor allem für die Anwendung der Modelle in der Praxis relevant ist.
Teuken-7B steht in einer Version für Forschungszwecke zur Verfügung und in einer unter der Lizenz «Apache 2.0». Diese können Unternehmen neben Forschung auch für kommerzielle Zwecke nutzen und in eigene KI-Anwendungen integrieren
- Download-Möglichkeit und Model Cards finden sich unter folgendem Link: https://huggingface.co/openGPT-X
- Für technisches Feedback, Fragen und Fachdiskussionen steht der Fachcommunity der OpenGPT-X Discord Server zur Verfügung: https://discord.gg/RvdHpGMvB3
- Speziell für Unternehmen besteht zudem die Möglichkeit, an kostenfreien Demoterminen teilzunehmen, in denen Fraunhofer-Wissenschaftlerinnen und Wissenschaftler erläutern, welche Anwendungen mit Teuken-7B realisiert werden können. Die Anmeldung zu Demoterminen ist über www.iais.fraunhofer.de/opengpt-x möglich.
- Ausführliche technische Hintergrundinformationen und Benchmarks sowie eine Übersicht aller Forschungsergebnisse des Projekts OpenGPT-X finden sich auf der Projektwebseite: https://opengpt-x.de/en/models/teuken-7b

{kind=link}